这一篇只是存档作用啦,因为之前的旧集群又搬走了,不过还好整体是跑的docker,迁移起来还是很容易的。
这个是一个快速搭建一个线上的Dos游戏的yaml文件。挺好玩的就先留下来
[……]

今天在图书馆偶遇了一本书,书名就是上面写着的《每天5分钟玩转Kubernetes》,让我想到了之前在IBM社区里面看到的一个五分钟openstack的系列。看着书篇幅不大,就一百来页,所以就随手翻翻,也作为自己对K8S的入门,后面没准整站的系统需要从Swarm向K8S迁移了。
由于属性SWARM所以使用类比的方法,可以很好的理解K8S的设计。整本书大概花了7个?番茄时钟翻完。之前选择Swarm由于Docker本身就包含了这个组件,简单易得。这本书看完之后,发现K8s很多特性解决了现在的问题,结论是k8s更加优秀,比如在卷管理的地方,之前Swarm如果要实现的话需要用上NFS,就很麻烦,而K8S默认的就是多节点同步。等等的特性后面再写吧。迟早换。
[……]
由于自己的本地主机的情况发生了重大变化,本地的两主机小机器的使命算是完成了。所以,最后没办法不得不上云了。网站整体的内容和域名不作改变。
还好还好,基于 Docker 的部署,所以整体的迁移是相当相当的方便的。本来想着折腾好久要,最后发现,前前后后没到20分钟,就差不多搞定了,也顺便解决了之前部署中的一些BUG。这一篇,主要就是记录迁移过程中的各种操作,后面可以很方便的进行复用。
[……]
在之前有用 Cadvisor,influx 来搭建了一套监控系统。实现各个容器的运行情况的监控。不过实际上感觉这个东西的功能真的是十分的鸡肋。除了几个简简单单的性能监控的指标就没有了。
说白了就是可欣赏型还是有的,可操作性就是没有了。不过这里给放个图
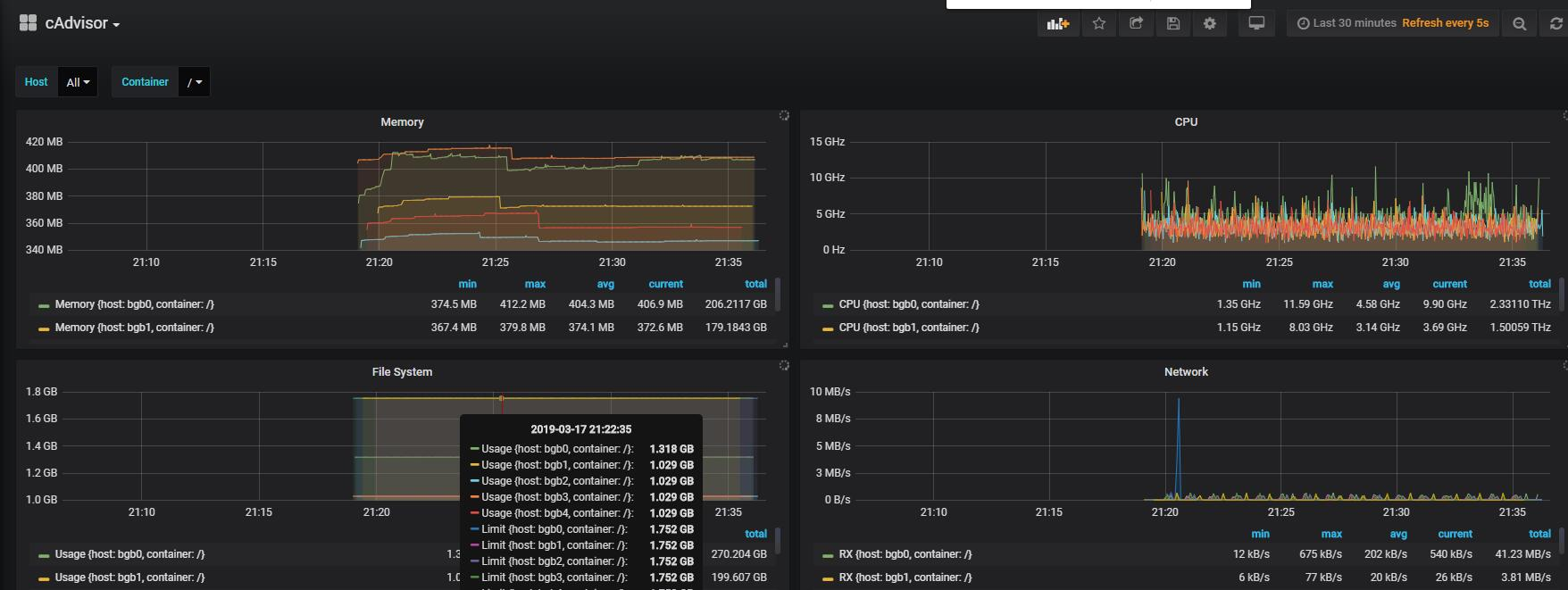
监控的效果,整体看起来还是很炫酷的。(可是真的没啥用)。而且设定的一周的数据生命周期,到后面单单的influxdb的卷也是占了2G的空间。所以这个功能羸弱,加上机能受限,后面就直接 remove 了这个 stack。
但是一想,监控还是要有的。怎么办呢,后面就是遇上了 Prometheus这样个东西。(后面还想实现服务的自动扩缩容)所以,就打算整个一套的基于 Prometheus 的监控,可视化以及自动扩缩容的系统。
所以先从监控系统的搭建开始熟悉 Prometheus 了。
推荐阅读:
IBM Dev 的 Prometheus 入门与实践
如何快速部署 Prometheus?- 每天5分钟玩转 Docker 容器技术(85)
[……]
在这篇POST里面,主要记录,如何把后台的反代工具从 Nginx 切换到 traefik 的过程。实现Docker 的网络中更加优雅反代。
较之Nginx 的最大的特点,容器(服务)的网络,不必再通过ingress(虚拟入口),来把端口映射到host的网络上,而导致,占有了一大堆一大堆的 奇怪的端口 :30000,32767... 所以下面就简单的介绍一下Traefik:
[……]
上一篇已经很OK的部署了一个 wordpress 的stack跑在Swarm 的集群上面,现在还挺稳定的,比较开心。
不过为了追求更快更好的体验,和对页面体验的提升,这里就要进行大优化了。
因为描述一下现状,现在的中间的隧道节点是很可怜的 1M 带宽的机器,怎么把这个 1M 的带宽用好就是关键了。
这里先给个数据:站点的加载内容为 205k

1M 带宽其理论上下行总和速度 : 125k/s
理论传输时间:205/125=1.64s
实际上传输时间: 2.6s +- 0.5
Not Special ,It’s unique
[……]
在有了前面的 Docker 的 PaaS 的管理,在这里一切变得简单起来了,写好 Compose 的文件,一个简简单单的 stack deploy 就可以直接跑起了这个服务栈,美哉美哉。
而且作为一个综合的建站的项目,涉及到的东西,还是相当的多的,从前面的建站,到后面的优化部分,笔者也算是投入了比较多的时间,这里总结整个过程,以及各种遇到的问题。另外这里的 compose 的文件都是可以直接使用的。 意味着,你也可以很轻松的搭建起一个 基于 Docker 的 wordpress 平台
(你所看到的内容是笔者因为没有开自动保存,第二次敲上去的 ?)
[……]