
前
在之前有用 Cadvisor,influx 来搭建了一套监控系统。实现各个容器的运行情况的监控。不过实际上感觉这个东西的功能真的是十分的鸡肋。除了几个简简单单的性能监控的指标就没有了。
说白了就是可欣赏型还是有的,可操作性就是没有了。不过这里给放个图
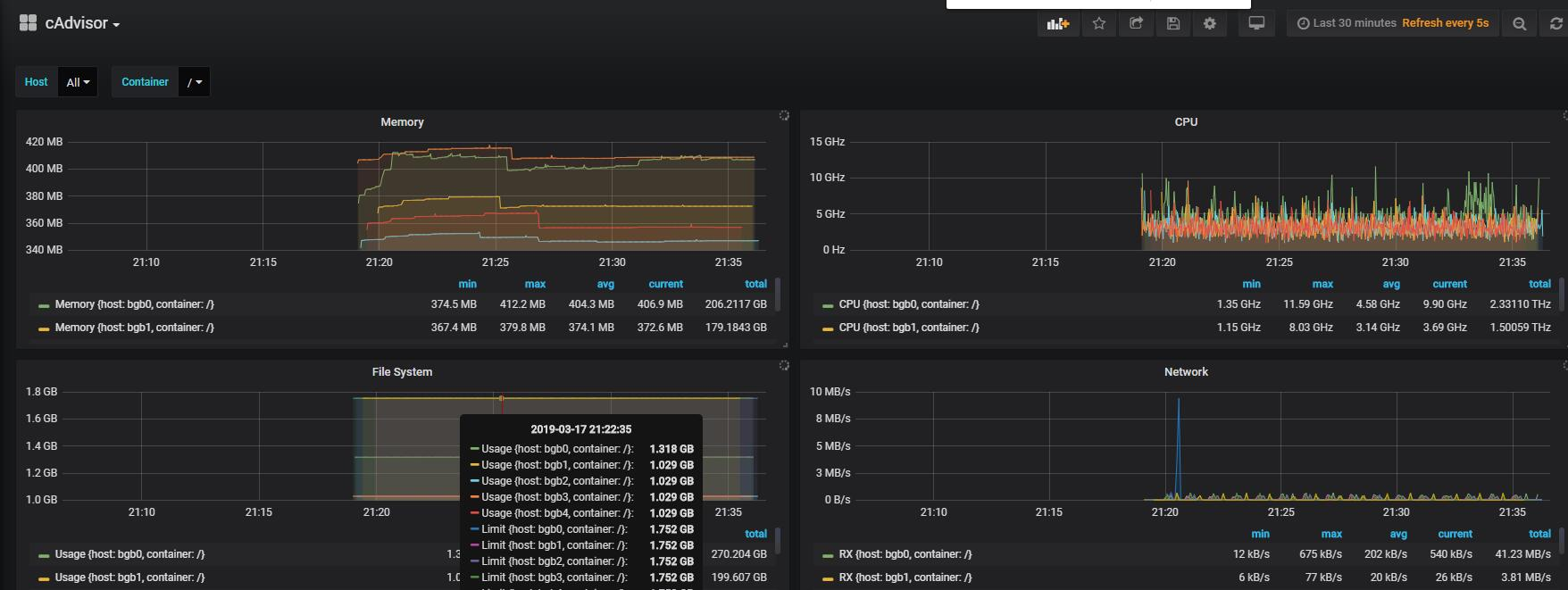
监控的效果,整体看起来还是很炫酷的。(可是真的没啥用)。而且设定的一周的数据生命周期,到后面单单的influxdb的卷也是占了2G的空间。所以这个功能羸弱,加上机能受限,后面就直接 remove 了这个 stack。
但是一想,监控还是要有的。怎么办呢,后面就是遇上了 Prometheus这样个东西。(后面还想实现服务的自动扩缩容)所以,就打算整个一套的基于 Prometheus 的监控,可视化以及自动扩缩容的系统。
所以先从监控系统的搭建开始熟悉 Prometheus 了。
推荐阅读:
IBM Dev 的 Prometheus 入门与实践
如何快速部署 Prometheus?- 每天5分钟玩转 Docker 容器技术(85)
快速部署
这里的部署环境一样,使用 Docker 来进行快速部署,PaaS 的便利,简直爱死。不需要再一个个的手动下载和配置,直接写好 compose 文件,之后直接部署上去,就已经成功了一半了。后面再针对配置文件进行修改就OK了。(Docker 就是应用的标准化)
这里直接给出 docker-compose.yml了。前面写多了慢慢的有了感觉了,想要什么就直接写上去吧,整个过程和搭积木一样,再也不会被困于各种的问题啊,环境啊依赖啊之类的东西里面去了。美哉美哉。
compose 文件如下,这里初步实现监控功能,所以alert暂时没有加上去。使用 Prometheus,node-exporter,grafana 分别作为数据查询,数据采集,和数据可视化这几大部分,下面就直接贴出配置文件了,没有什么技巧
version: '3'
services:
node-exp:
# 网络中使用 9100端口
image: prom/node-exporter
restart: always
deploy:
# 需要全局部署
mode: global
grafana:
image: grafana/grafana
restart: always
ports:
- 3000:3000
volumes:
- grafana:/var/lib/grafana
depends_on:
- influx
deploy:
replicas: 1
placement:
constraints:
- node.role == manager
prometheus:
image: prom/prometheus
ports:
- 9090:9090
command: --config.file="/usr/local/src/file/prometheus.yml"
volumes:
- config:/usr/local/src/file/
deploy:
replicas: 1
placement:
constraints:
- node.role == manager
volumes:
config:
driver_opts:
type: "nfs4"
o: "addr=192.168.1.230,nolock,soft,rw"
device: ":/srv/nfs/mon_config/"
grafana:在上面的Stack部署完成之后,Prometheus 还需要一个 配置文件,我们需要根据示例文件进行修改,并且挂载到 服务内部。配置内容如下:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label <code>job=<job_name></code> to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: 'linux'
static_configs:
- targets: ['node-exp:9100']
labels:
instance: node
这里还没有启用告警,所以上面的alertmanager 就先留空了。如果上面的配置没有问题的话,检查容器和服务状态,都是 running 且 log 无异常,基本就完成配置了。

示例状态如上图。
可视化的快速配置
再我们的数据源配置完成之后,就可以使用 Grafana 进行数据可视化了。直接访问 web,默认的account 是 admin/admin 修改之后,根据向导,导入数据源。
后面就是奇迹的时刻,直接导入视图即可。(grafana 提供了很好的试图分享的功能)我们用别人的好看的,自己就不用再费大力气了。
使用如下视图
之后直接进行 import,神奇就这样发生了。

下面是可视化界面的截图:
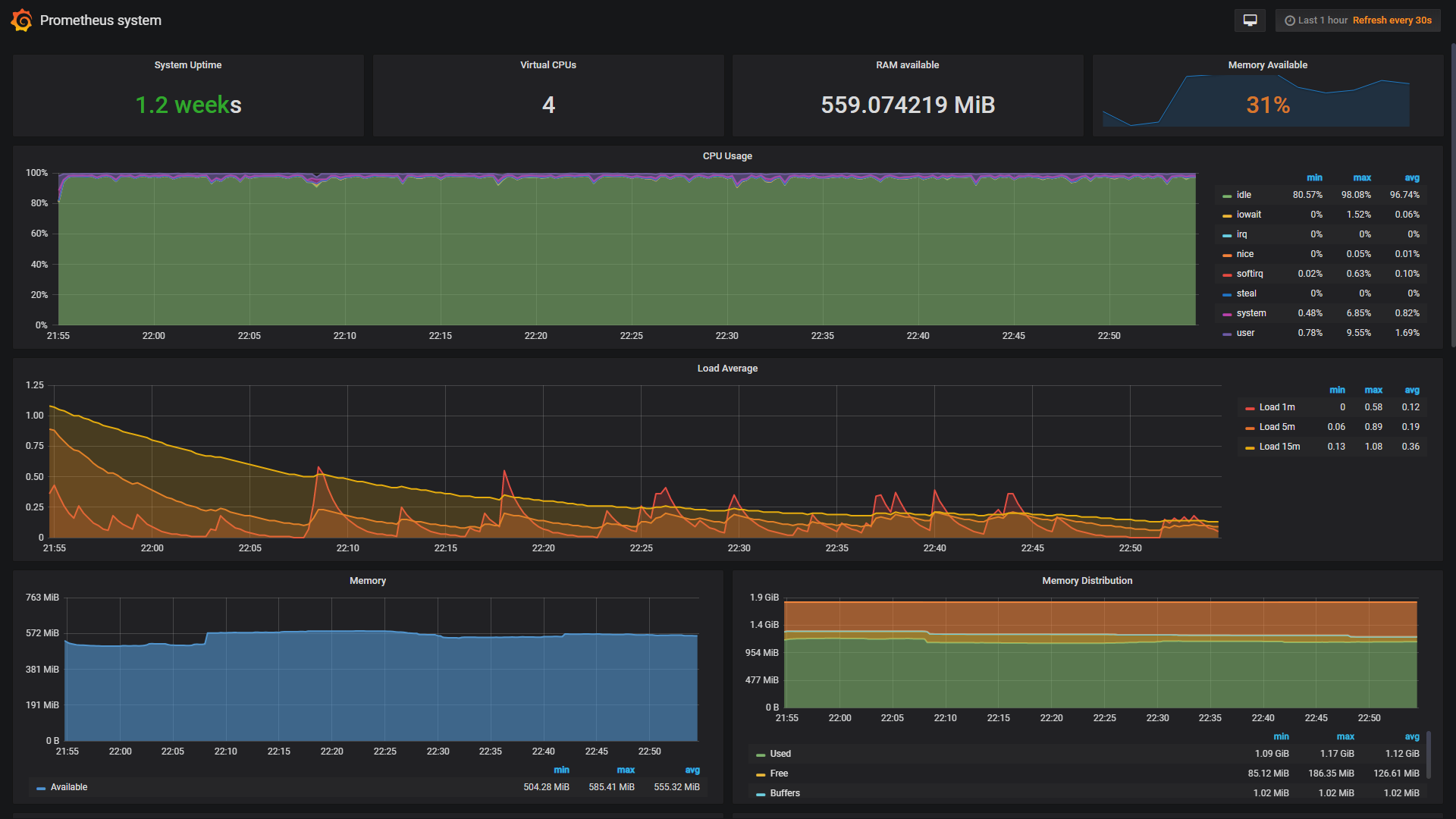
美观,大方,优雅~
后面的话
再次为 Docker 的平台提供的方便感到惊喜,的确这种应用标准化的思想,解放了太多的生产力。
下面一篇,应该要开始介入 alertmanager 实现自动扩缩容的操作了。
监控整体运行平稳,问题在于,这里的 设置的 node-exporter 的hostname指的是 vip 所以这个拉去的是两主机 RR 返回的结果